From the ashes of the database revolution...
With NoSQL and Hadoop, the database world has undergone a revolution. The fighting reached its peak a couple of years ago, but things have calmed down since, and now is a good time to take stock of old and new style data management technologies.
From this revolution, we can learn a lot about what databases should, and should not be. At the end of this post, I propose a system, called Optiq, that would restore to NoSQL/Hadoop systems some of the good features of databases.
Learning from history
Revolutions tend to follow patterns. George Orwell allegorized the progress of the Russian Revolution in his novel Animal Farm. He described the injustices that were the trigger for the revolution, the new egalitarian value system established after the revolution, and the eventual corruption of those values. Revolutions are an opportunity to introduce new ideas, not all of them good ones. For example, the French revolution put in place a decimal system, and though they kept the kilogramme and the metre, they were forced to quickly relinquish the 10 hour day and the 10 day week when the workers discovered that they’d been conned out of 30% of their weekend time.
We see all of these forces at play in the database revolution. The triggers for the revolution were the requirements that traditional RDBMSs could not meet (or were not meeting at the time). The revolution adopted a new paradigm, introduced some new ideas, and threw out some old ideas. I am interested in which of those old ideas should be reinstated under the new regime.
I am a database guy. I was initially skeptical about the need for a revolution, but a couple of years ago I saw that Hadoop and NoSQL were gaining traction, had some good ideas, growing momentum, and were here to stay. My prediction is that traditional and new data management systems will grow more and more similar in appearance over the next 5-10 years. Traditional RDBMSs will adopt some of the new ideas, and the new systems will support features that make them palatable to customers accustomed to using traditional databases.
But first, some terminology. (As George Orwell would agree, what you call something is almost as important as what it is.)
- I call the new breed of systems “data management systems”, not “databases”. The shift implies something less centralized, more distributed, and about processing as well as just storing and querying data. Or maybe I’m confusing terminology with substance.
- I distinguish NoSQL systems from Hadoop, because Hadoop is not a data management system. Hadoop is a substrate upon which many awesome things can, and will, be built, including ETL and data management systems.
- NoSQL systems are indeed databases, but they throw out several of the key assumptions of traditional databases.
- I’m steering clear of the term “Big data” for reasons I’ve already made clear.
The good stuff
In the spirit of post-revolutionary goodwill, let’s steer clear of our pet gripes and list out what is best about the old and new systems.
Good features from databases
- SQL language allows integration with other components, especially components that generate queries and need to work on multiple back-ends.
- Management of redundant data (such as indexes and materialized views), and physically advantageous data layout (sorted data, clustered data, partitioned tables)
- ACID transactions
-
High-performance implementations of relational operators
- Explicit schema, leading to concise, efficient queries
Good features from Hadoop/NoSQL systems
- Easy scale-out on commodity hardware
- Non-relational data
- User-defined and non-relational operators
- Data is not constrained by schema
Scale and transactions
Scale-out is key. The new data systems all run at immense scale. If traditional databases scaled easily and cheaply, the revolution would probably not have happened.
There are strong arguments for and against supporting ACID transactions. Everyone agrees that transactions have high value: without them, it is more difficult to write bug-free applications. But the revolutionaries assert that ACID transactions have to go, because it is impossible to implement them efficiently. Newer research suggests that there are ways to implement transactions at acceptable cost.
In my opinion, transactions are not the main issue, but are being scapegoated because of the underlying problem of scalability. We would not be having the debate – indeed, the whole NoSQL movement may not have occurred – if conventional databases had been able to scale as their users wanted.
To be honest, I don’t have a lot of skin in this game. As an analytic database technology, Optiq is concerned more with scalability than transactions. But it’s interesting that transactions, like the SQL language, were at first declared to be enemies of the revolution, and are now being rehabilitated.
Schema
Relational databases require a fixed schema. If your data has a schema, and the schema does not change over time, this is a good thing. Your queries can be more concise because you are not defining the same fields, types, and relationships every time you write a query.
Hadoop data does not have a schema (although you can impose one, after the event, using tools such as Pig and Hive).
The ideal would seem to be that you can provide a schema if the data conforms to a fixed format, provide a loose schema if, say, records have variable numbers of fields, or operate without one. In Hadoop, as in ETL tools, data is schema-less in early stages of a pipeline, stronger typing is applied in later stages of the pipeline, as fields are parsed and assigned names, and records that do not conform to the required schema are eliminated.
Location, control and organization of data
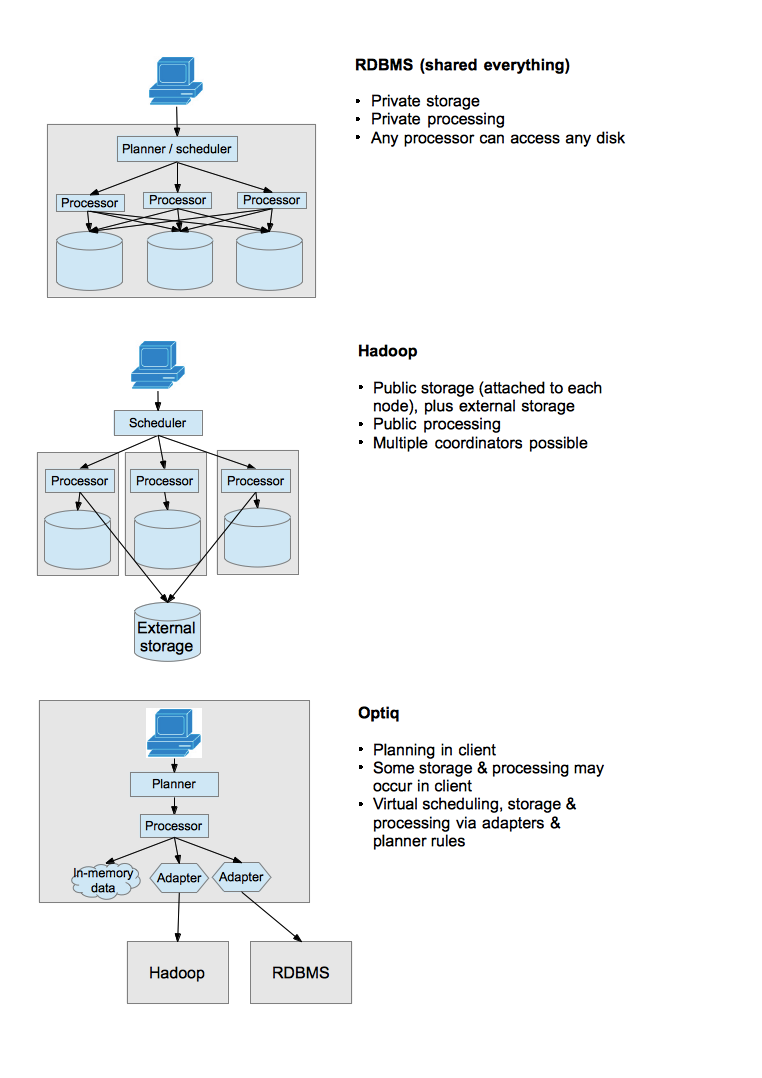
Traditional databases own their storage. Their data resides in files, sometimes entire file systems, that can only be accessed by the database. This allows the database to tightly control the access to and organization of the data. But it means that the data cannot be shared between systems, even between databases made by the same vendor.
Hadoop clusters are expensive, but if several applications share the same cluster, the utilization is kept high, and the cost is spread across more departments’ budgets. Applications may share data sets, not just processing resources, but they access the data in place. (That place may or may not be HDFS.) Compared to copying data into an RDBMS, sharing data reduces the saves both time and money.
Lastly, the assumption that data is shared encourages applications to use straightforward formats for their data. A wide variety of applications can read the data, even those not envisioned when the data format was designed.
SQL and query planning
SQL is the hallmark of an RDBMS (at for those of us too young to remember QUEL). SQL is complicated to implement, so upstart open source projects, in their quest to implement the simplest thing that could possibly work have been inclined to make do with less powerful “SQL-like” languages. Those languages tend to disappoint, when it comes to interoperability and predictability.
But I contend that SQL support is a consequence of a solid data management architecture, not the end in itself. A data management system needs to accept new data structures and organizations, and apply them without rewriting application code. It therefore needs a query planner. A query planner, in turn, requires a metadata catalog and a theoretically well-behaved logical language, usually based on relational algebra, for representing queries. Once you have built these pieces, it is not a great leap to add SQL support.
The one area that SQL support is essential is tool integration. Tools, unless written for that specific database, want to generate SQL as close to the SQL standard as possible. (I speak from personal experience, having written Mondrian dialects for more than a dozen “standards compliant” databases.) Computer-generated SQL is not very smart – for example, you will often see trivial conditions like “WHERE 1 = 1” and duplicate expressions in the SELECT clause – and therefore needs to be optimized.
Flat relational data
There is no question that (so-called “flat”) relational data is easier for the database to manage. And, we are told, Ted Codd decreed forty years ago that relational data is all we should ever want. Yet I think that database users deserve better.
Codd’s rules about normalization have been used to justify a religious war, but I think his point was this. If you maintain multiple copies of the same information, you’ll get into trouble when you try to update it. One particular, and insidious, form of redundant information is the implicit information in the ordered or nested data.
That said, we’re grown ups. We know that there are risks to redundancy, but there are significant benefits. The risks are reduced if the DBMS helps you manage that redundancy (what are indexes, anyway?), and the benefits are greater if your database is read much more often than it is updated. Why should the database not return record sets with line-items nested inside their parent orders, if that’s what the application wants? No reason that I can think of.
In summary, a data management system should allow “non-flat” data, and operations on that data, while keeping a semantics based, as far as possible, on the relational algebra.
Introducing Optiq
Optiq aims to add the “good ideas” from traditional databases onto a new-style Hadoop or NoSQL architecture.
To a client application, Optiq appears to be a database that speaks SQL and JDBC, but Optiq is not a database. Whereas a database controls storage, processing, resource allocation and scheduling, Optiq cedes these powers to the back-end systems, which we call data providers.
Optiq is not a whole data management system. It is a framework that can mediate with one or more data management systems. (Optiq could be configured and distributed with a scheduler, metadata layer, data structures, and algorithms, so that it comes out of the box looking like a database. In fact, we hope and expect that some people will use it that way. But that is not the only way it is intended to be used.)
The core of the framework is the extensible query planner. It allows providers to specify their own type systems, operators, and optimizations (for example, switching to a materialized view, or eliminating a sort if the underlying file is already sorted). It also allows applications to define their own functions and operators, so that their application logic can run in the query-processing fabric.
An example
You might describe Optiq as a database with the hood open, accessible to anyone who wants to tinker with the engine. Here is a simple example:
Class.forName("net.hydromatic.optiq.jdbc.Driver");
Connection connection =
DriverManager.getConnection("jdbc:optiq:");
OptiqConnection optiqConnection =
connection.unwrap(OptiqConnection.class);
JavaTypeFactory typeFactory = optiqConnection.getTypeFactory();
optiqConnection.getRootSchema().add("HR",
new CsvSchema("/var/flatfiles/hr", typeFactory));
ResultSet resultSet =
connection.createStatement().executeQuery(
"SELECT e.name, e.sal, d.name AS department\n" +
"FROM hr.emps AS e, hr.depts AS d\n" +
"WHERE e.deptno = d.deptno\n" +
"ORDER BY e.empno");
while (resultSet.next()) {
System.out.println(
"emp=" + resultSet.getString(1) +
", sal=" + resultSet.getInt(2) +
", department=" + resultSet.getString(3));
}
resultSet.close();The program requires a directory, /var/flatfiles/hr, containing
the files EMPS.csv and DEPTS.csv. Each file has a header record
describing the fields, followed by several records of data.
There is no other data or metadata, and in fact CsvSchema is an
extension, not a built-in part of the system.
When the connection is opened, the virtual database is empty. There
are no tables, nor even any schemas. The getRootSchema().add( ... )
call registers a schema with a given name. It is like mounting a
file-system.
Once the CsvSchema is registered with the connection with the name
“HR”, Optiq can retrieve the table and column metadata to parse and
optimize the query. When the query is executed, Optiq calls
CsvSchema’s implementations of linq4j’s
Enumerable
interface to get the contents of each table, applies built-in Java
operators to join and sort the records, and returns the results
through the usual
JDBC ResultSet interface.
This example shows that Optiq contains a full SQL parser, planner and implementations of query operators, but it makes so few assumptions about the form of data and location of metadata that you can drop in a new storage plugin in a few lines of code.
Design principles
The design of the Optiq framework is guided by the following principles.
- Do not try to control the data, but if you know about the data organization, leverage it.
- Do not require a schema, but if you know about the shape of the data, leverage it.
- Provide the SQL query language and JDBC interface, but allow other languages/interfaces.
- Support linq4j as a backend, but allow other protocols.
- Delegate policy to the data providers.
Let’s see how Optiq brings the “good ideas” of databases to a NoSQL/Hadoop provider.
Applying these principles to schemas, Optiq can operate with no, partial, or full schema. Data providers can determine their own type system, but are generally expected to be able to operate on records of any type: that may be a single string or binary field, and may contain nested collections of records. Since Optiq does not control the data, if operating on a schema-less provider like Hadoop, Optiq would apply its schema to already loaded data, as Pig and Hive do. If Optiq is assured that the data is clean (for example, a particular field is always an integer) then it may be able to optimize.
Optiq’s type system allows records to contain nested records, and provides operators to construct and destruct nested collections. Whereas SQL/JDBC queries do not stretch the type system, linq4j gives Optiq a workout: it needs to support the Java type system and operations such as selectMany and groupBy that operate on collection types.
Lastly, on breaking down the rigid boundary between database and application code.
My goal in data-oriented programming is to allow applications, queries, and extension functions and operators to be written in the same language – and if possible using the same programming model, and on the same page of code – and distributed to where query processing is taking place.
The paradigms should be the same, as far as possible. (MapReduce fails this test. Even though MapReduce is Java, one would not choose to write algorithms in this way if there was not the payoff of a massively scalable, fault-tolerant execution infrastructure. Scalding is an example of a DSL that succeeds in making queries fairly similar to “ordinary programming”.)
That said, Optiq is not going to fully solve this problem. It will be a research area for years to come. LINQ made a good start. Optiq has a query planner, and is open and extensible for front-end query languages, user-defined operators, and user-defined rules. Those tools should allow us to efficiently and intelligently push user code into the fabric of the query-processing system.
Conclusion
Optiq attempts to create a high-level abstraction on top of Hadoop/NoSQL systems that behaves like a database but does not dilute the strengths of the data provider. But it brings in only those features of databases necessary to create that abstraction; it is a framework, not a database.
Watch this space for further blog posts and code. Or catch me at Hadoop Summit next week and ask me for a demo.