Streaming analytics over content feeds (and how content feeds could be better)
We have been experimenting with different web-based data sources for SQLstream. Seth Grimes saw the demo, and wrote a piece “BI on Content Feeds, a.k.a. Continuous (Twitter) Transformation” in Intelligent Enterprise.
Social networks and web content feeds such as RSS have, in a few short years, added a dynamic component to the vast static content on the web. As less-sophisticated users have become more accustomed to consuming them, these feeds have become a ubiquitous part of the web experience.
Web feeds have an information content that is at present untapped. In the same way that a radical new approach – the search engine – was needed to harness the static information content of the web, a streaming analytics solution in this area becomes important sooner rather than later.
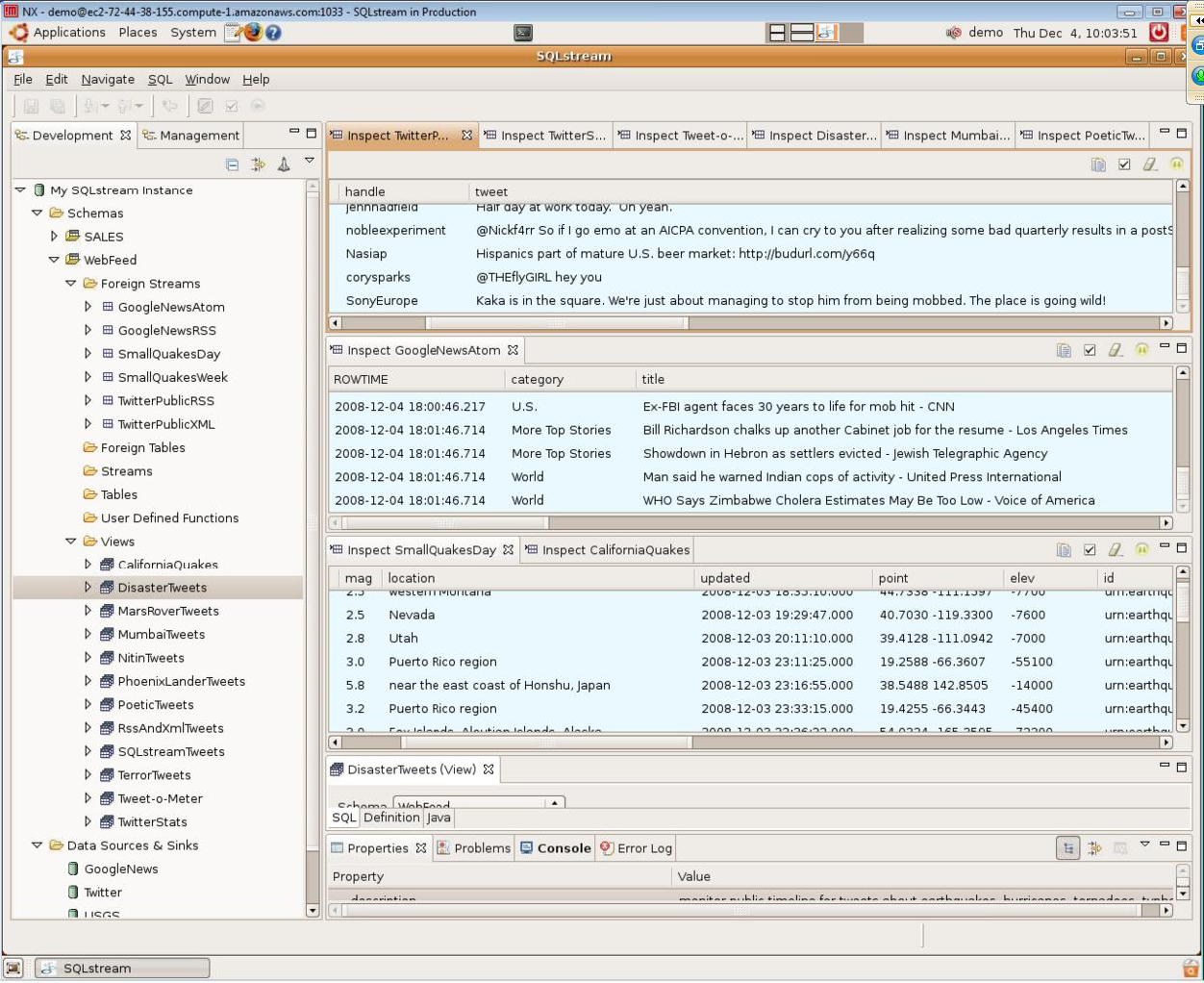
The SQLstream prototype illustrates how several data formats (tweets from Twitter, USGS quake data in RSS format, news from Google’s Atom feed, and so forth) can be integrated into SQLstream.
For each data format we built an adapter that implemented the SQL/MED specification, and using these adapters we mapped each feed into SQLstream as a foreign stream. Once data is in SQL format, you can build views on top of these streams to filter, join and aggregate records.
Now we’ve done the hard part – getting the data feeds into a common format – there are plenty of ways to extract information from the feeds. For instance, it would be easy to find out which Twitter users are the most active over the last hour or the last seven days.
Or you could pull apart messages to discover word frequencies, and write a stream that detects words that are being used more frequently than usual (similar to Google zeitgeist but in real time).
But the prototype has some limitations: news items tend to arrive in bursts every couple of minutes, and many Twitter messages are missing. These are all limitations of the data sources with respect to latency (how soon messages arrive) and throughput (how many messages per second the system can handle), and the limitations stem from the inefficiencies of the web feed protocols.
You would think that something called a ‘feed’ would push content to subscribers as soon as it arrives, but in fact RSS and the other feed types in the prototype use a pull protocol. With a pull protocol, the subscriber needs to continually poll the feed to get the content (typically an XML document a few kilobytes long), parse the content, and figure out what, if anything, is new since the last time we polled.
This process soaks up a lot of network bandwidth and resources for both the provider and the subscriber, and the cost goes up the more regularly we poll. Typically the provider has to throttle the feed to prevent their servers from being overwhelmed. For example, Twitter updates its feed only once per minute and limits the number of tweets on the page. At times of high volume, only a small percentage of tweets make it into the feed.
This may not sound that serious if the content is a twitter conversation between friends, or a blog with one or two posts a week. But web feed protocols are becoming part of the IT infrastructure, and business users require lower latency, higher throughput and higher availability. (The existence of services like Gnip is evidence of the need to control the web content chaos.)
I would like to see the emergence of a genuine ‘push’ protocol for web-based content. It doesn’t have to be particularly complicated. To illustrate what I have in mind, here is an example of a simple, stateless protocol, built using XML over HTTP, like the current feed formats. A subscriber sends a request
<readRequest>
<minimumRowtime>2008-12-04 18:00:46.000</minimumRowtime>
<maximumCount>1000</maximumCount>
<maximumWait>10s</maximumWait>
</readRequest>over HTTP, and the provider replies with a set of content records
<rows>
<row>
<rowtime>2008-12-04 18:00:46.217</rowtime>
<category>U.S.</category>
<title>Ex-FBI agent faces 30 years to life for mob hit - CNN</title>
</row>
<row>
<rowtime>2008-12-04 18:00:46.714</rowtime>
<category>More Top Stories</category>
<title>Bill Richardson chalks up another Cabinet job for the resume - Los Angeles Times</title>
</row>
<row>
<rowtime>2008-12-04 18:00:48.104</rowtime>
<category>More Top Stories</category>
<title>Showdown in Hebron as settlers evicted - Jewish Telegraphic Agency</title>
</row>
</rows>According to the protocol, the provider sends the results after 10 seconds, or when there are 1000 records to return, whichever occurs sooner. After it has received a result, the subscriber will typically ask for the next set of rows with a higher rowtime threshold.
Even though it is simple, the protocol ensures that data flows efficiently for feeds of all data rates. For a high volume feed, the 1000 record limit will be reached before the 10 second timeout, so latency naturally decreases. For a low volume feed, many requests may time out and return an empty result; but the 10 second wait limits the number of requests per minute that the server has to handle.
Naturally, I have in mind an even better protocol that allows subscribers to submit SQL queries, and of course every web would have a SQLstream server behind the curtain. But seriously folks… I would be satisfied with a lot less than that. A simple, open protocol for streaming content syndication would unlock the web and make it the medium of choice for streaming as well as static content.